

در دنیای شتابدهندههای هوش مصنوعی و محاسبات با عملکرد بالا (HPC)، رقابت میان تولیدکنندگان بزرگی مانند AMD و Nvidia به نقطه اوج خود رسیده است. در این مقاله، به بررسی شتابدهنده قدرتمند AMD Instinct™ MI300X و مقایسه آن با Nvidia H100 80GB میپردازیم تا تواناییها و نقاط قوت هر یک را برای کاربردهای هوش مصنوعی و HPC روشن کنیم.
شتابدهنده AMD Instinct MI300X Accelerator با ظرفیت حافظه 192 گیگابایت HBM3 و پهنای باند حافظه 5.3 ترابایت بر ثانیه، یکی از قدرتمندترین گزینهها برای بارهای کاری هوش مصنوعی و HPC محسوب میشود. این شتابدهنده با 19,456 پردازنده استریم، معماری CDNA3 و فرآیند ساخت 5 نانومتری TSMC FinFET، توان محاسباتی FP8 معادل 5.22 PFLOPs را ارائه میدهد.
از سوی دیگر، شتابدهنده Nvidia H100 با ظرفیت حافظه 80 گیگابایت HBM2e و پهنای باند حافظه 3.4 ترابایت بر ثانیه طراحی شده است تا پاسخگوی نیازهای مشابه باشد. این محصول با 16,896 هسته CUDA، معماری Hopper و فرآیند ساخت 4 نانومتری TSMC FinFET، توان محاسباتی FP8 حداکثر 3.96 PFLOPs را فراهم میکند.
در بخش تواناییهای هوش مصنوعی، AMD Instinct MI300X Accelerator توانسته است در برخی موارد عملکرد بهتری نسبت به Nvidia H100 نشان دهد. بهعنوان مثال:
پهنای باند حافظه MI300X معادل 5.3 ترابایت بر ثانیه است، در حالی که H100 پهنای باندی برابر با 3.4 ترابایت بر ثانیه دارد. این اختلاف، MI300X را برای کاربردهایی که به انتقال سریع داده نیاز دارند، مانند شبیهسازیهای پیچیده و تحلیل دادههای بزرگ، به گزینهای برتر تبدیل میکند.
نمودار عملکرد هوش مصنوعی (AI Performance) تفاوت عملکرد میان AMD Instinct™ MI300X و Nvidia H100 را بهخوبی نشان میدهد. در سه حالت محاسباتی مختلف (TF32، FP16/BF16 و FP8)، MI300X در تمامی موارد عملکرد بهتری دارد. بهویژه در محاسبات FP8، MI300X با دستیابی به 5229.8 TFLOPs بهطور قابلتوجهی از H100 با 3957.8 TFLOPs پیشی گرفته است. این امر برای بارهای کاری هوش مصنوعی که نیاز به پردازش موازی گسترده دارند، اهمیت ویژهای دارد.
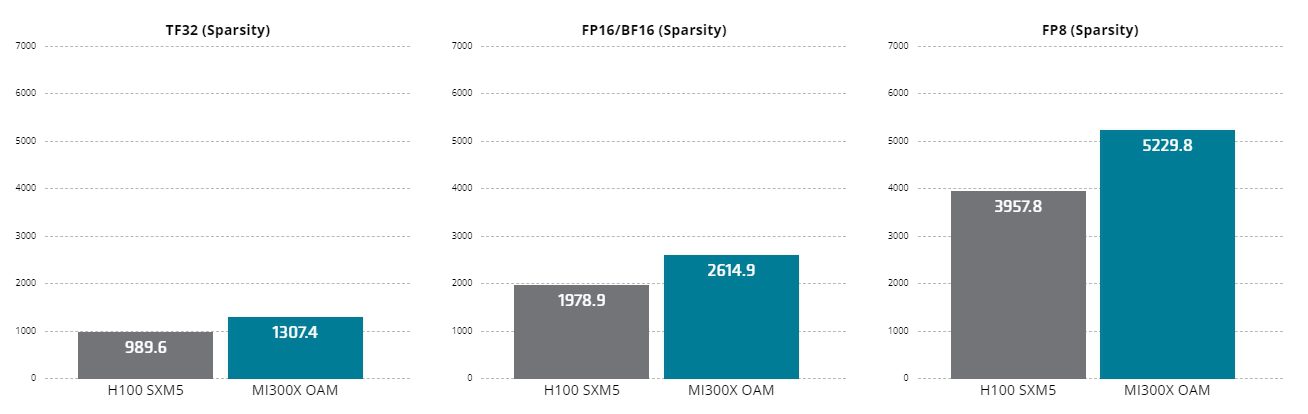
همچنین، در محاسبات TF32 و FP16/BF16، MI300X بهترتیب با 1307.4 و 2614.9 TFLOPs از H100 با 989.6 و 1978.9 TFLOPs برتری دارد، که این تفاوت عملکرد در بارهای کاری حساس به دقت محاسباتی به چشم میآید.
نمودار عملکرد HPC نشان میدهد که AMD Instinct™ MI300X در تمامی مقادیر عددی، از Nvidia H100 پیشی گرفته است. در محاسبات FP64 (Vector)، MI300X با دستیابی به 81.7 TFLOPs، عملکردی بیش از دو برابر H100 با 33.5 TFLOPs ارائه میدهد. همچنین، در محاسبات FP64 (Tensor/Matrix)، MI300X با 163.4 TFLOPs نسبت به H100 با 66.9 TFLOPs برتری چشمگیری دارد. این مقادیر در محاسبات FP32 نیز مشابه است و MI300X با 163.4 TFLOPs همچنان نسبت به H100 با 66.9 TFLOPs، قدرت بیشتری نشان میدهد.





این اعداد و ارقام نشان میدهند که MI300X برای بارهای کاری HPC که نیاز به محاسبات برداری و ماتریسی سنگین دارند، انتخابی بیرقیب است.
یکی از مهمترین عوامل در ارزیابی شتابدهندهها، ظرفیت و پهنای باند حافظه است. AMD Instinct™ MI300X با ارائه ظرفیت حافظه 192 گیگابایت HBM3، بیش از دو برابر ظرفیت Nvidia H100 با 80 گیگابایت HBM2e را داراست. این اختلاف به MI300X اجازه میدهد تا بارهای کاری حجیمتری را مدیریت کند و بهویژه برای مدلهای هوش مصنوعی بزرگ (LLMs) بسیار مناسب است.

از نظر پهنای باند حافظه نیز MI300X با پهنای باند 5.3 ترابایت بر ثانیه، نسبت به H100 با 3.4 ترابایت بر ثانیه برتری قابل توجهی دارد. این میزان پهنای باند، توانایی انتقال دادههای سریعتر را فراهم کرده و کارایی بیشتری در پردازشهای سنگین به ارمغان میآورد.
یکی از جنبههای مهم در انتخاب شتابدهندهها، پشتیبانی نرمافزاری آنها است. AMD Instinct™ MI300X از پلتفرم نرمافزاری ROCm پشتیبانی میکند که یک اکوسیستم متنباز برای محاسبات با عملکرد بالا و هوش مصنوعی است. این پلتفرم به توسعهدهندگان اجازه میدهد تا با ابزارهای پیشرفته بهینهسازی و پیادهسازی بارهای کاری بپردازند. در مقابل، Nvidia H100 با پشتیبانی از پلتفرم CUDA و کتابخانههای متعدد مانند cuDNN و TensorRT، برای بسیاری از توسعهدهندگان و پروژههای موجود آشناتر و سازگارتر است.
MI300X با توان طراحی حرارتی (TDP) 750 وات عرضه میشود، در حالی که H100 با TDP حدود 700 وات کمی بهینهتر عمل میکند. با این حال، عملکرد بالاتر MI300X در برخی سناریوها میتواند این اختلاف مصرف انرژی را توجیه کند.
شتابدهنده AMD Instinct MI300X Accelerator با ظرفیت حافظه بالا، پهنای باند بیشتر و تواناییهای محاسباتی قویتر در برخی جنبهها، بهویژه برای مدلهای هوش مصنوعی مولد و بارهای کاری HPC، برتری محسوسی نسبت به Nvidia H100 80GB دارد. با این حال، H100 همچنان در برخی سناریوها، بهویژه در زمینههای بهینهسازی انرژی، گزینه مناسبی است.
انتخاب بین این دو شتابدهنده به نیازهای خاص شما و نوع بار کاری بستگی دارد. اگر به ظرفیت حافظه بیشتر و توانایی پردازش بالا نیاز دارید، MI300X گزینه بهتری است، در حالی که H100 ممکن است برای کاربردهایی که بهینهسازی انرژی و هزینه اهمیت دارد، مناسبتر باشد.
جهت دریافت اطلاعات بیشتر با ما در تماس باشید
02142535- داخلی 117
