

پیشآموزش یک مدل بنیادی بزرگ برای هر سازمانی مناسب نیست، چرا که این فرآیند نیازمند سرمایهگذاری فراوان، تخصصهای بالا و دسترسی به مجموعههای داده گسترده میباشد. با این حال، زمانی که یک سازمان موفق به پیشآموزش و انتشار چنین مدلی میشود، دیگران قادر خواهند بود از آن به عنوان پایهای برای تطبیق با نیازهای خاص خود استفاده کنند و این امر موانع پذیرش هوش مصنوعی را به طرز چشمگیری کاهش میدهد.
این فرآیند پسآموزشی موجب افزایش تقاضای تجمعی برای محاسبات شتابدار در میان سازمانها و جامعه گسترده توسعهدهندگان میشود. مدلهای متنباز محبوب میتوانند صدها یا هزاران مدل مشتق داشته باشند که در حوزههای مختلف آموزش دیدهاند. توسعه این اکوسیستم از مدلهای مشتق برای کاربردهای متنوع ممکن است حدود 30 برابر محاسبات بیشتری نسبت به پیشآموزش مدل بنیادی اولیه نیاز داشته باشد.
تکنیکهای پسآموزشی میتوانند ویژگیهای خاص و ارتباط مدل با کاربرد مورد نظر یک سازمان را بهبود بخشند. در حالی که پیشآموزش مانند فرستادن یک مدل هوش مصنوعی به مدرسه برای یادگیری مهارتهای بنیادی است، پسآموزش مدل را با مهارتهایی که برای شغل مورد نظر کاربرد دارند تقویت میکند. برای مثال، یک مدل زبان بزرگ (LLM) میتواند پسآموزش داده شود تا وظایفی مانند تحلیل احساسات یا ترجمه را بر عهده گیرد — یا به اصطلاحات فنی یک حوزه خاص مانند بهداشت و درمان یا حقوق پی ببرد.
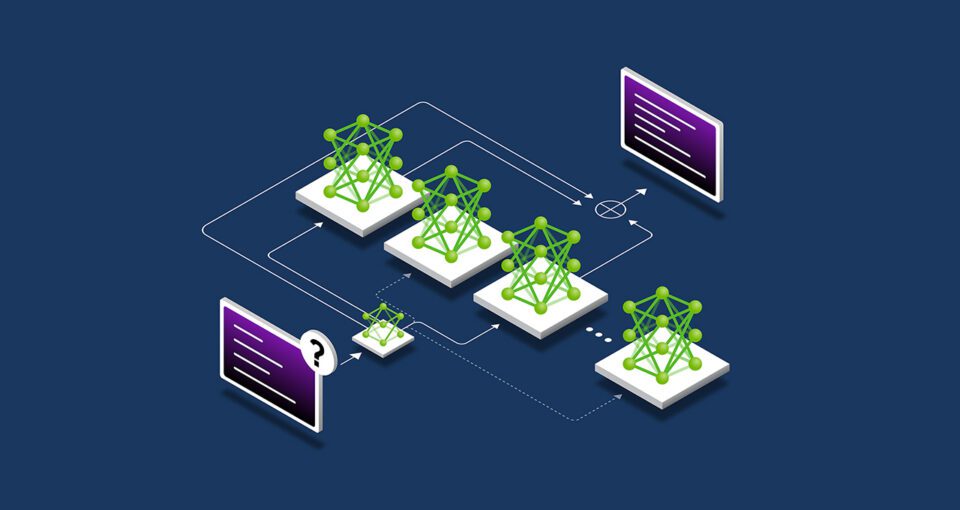
قانون مقیاسبندی پسآموزشی بیان میکند که عملکرد یک مدل پیشآموزش دادهشده میتواند از نظر کارایی محاسباتی، دقت یا ویژگیهای خاص حوزه با استفاده از تکنیکهایی مانند تنظیم دقیق (فاینتیونینگ)، هرس کردن، کوانتیزاسیون، تقطیر (دیستلیشن)، یادگیری تقویتی و افزایش دادههای مصنوعی بهبود یابد.
تنظیم دقیق (فاینتیونینگ) از دادههای آموزشی اضافی برای سفارشیسازی یک مدل هوش مصنوعی جهت حوزهها و کاربردهای خاص استفاده میکند. این کار میتواند با استفاده از مجموعه دادههای داخلی یک سازمان یا با جفتهای نمونه ورودی و خروجی مدل انجام شود.
تقطیر (دیستلیشن) به جفتی از مدلهای هوش مصنوعی نیاز دارد: یک مدل معلم بزرگ و پیچیده و یک مدل دانشآموز سبک. در رایجترین تکنیک تقطیر، که به آن تقطیر آفلاین گفته میشود، مدل دانشآموز یاد میگیرد تا خروجیهای مدل معلم پیشآموزش دادهشده را تقلید کند.
یادگیری تقویتی (RL) یک تکنیک یادگیری ماشینی است که از یک مدل پاداش برای آموزش یک عامل به منظور اتخاذ تصمیماتی که با یک کاربرد خاص همسو باشند استفاده میکند. این عامل سعی میکند با تعامل با محیط، تصمیماتی اتخاذ کند که پاداش تجمعی را در طول زمان به حداکثر برساند — برای مثال، یک مدل زبان چتبات که با واکنشهای مثبت کاربران (مثلاً علامت «انگشت بالا») تقویت میشود. این تکنیک به عنوان یادگیری تقویتی از بازخورد انسانی (RLHF) شناخته میشود. تکنیک دیگری، نوینتر، به نام یادگیری تقویتی از بازخورد هوش مصنوعی (RLAIF)، به جای آن از بازخورد مدلهای هوش مصنوعی برای هدایت فرآیند یادگیری استفاده میکند و تلاشهای پسآموزشی را سادهتر میسازد.
نمونهگیری بهترین از میان n یا (Best-of-n sampling) خروجیهای متعدد از یک مدل زبانی تولید کرده و آن خروجی با بالاترین نمره پاداش بر اساس یک مدل پاداش را انتخاب میکند. این روش اغلب برای بهبود خروجیهای هوش مصنوعی بدون تغییر پارامترهای مدل استفاده میشود و به عنوان جایگزینی برای تنظیم دقیق با یادگیری تقویتی مطرح است.
روشهای جستجو طیفی از مسیرهای تصمیمگیری احتمالی را پیش از انتخاب خروجی نهایی کاوش میکنند. این تکنیک پسآموزشی میتواند پاسخهای مدل را به طور تدریجی بهبود بخشد.
برای پشتیبانی از پسآموزش، توسعهدهندگان میتوانند از دادههای مصنوعی برای افزایش یا تکمیل مجموعه دادههای تنظیم دقیق خود استفاده کنند. تکمیل مجموعه دادههای دنیای واقعی با دادههای تولید شده توسط هوش مصنوعی میتواند به مدلها در بهبود تواناییشان برای پردازش موارد نادر یا کمنمایش دادههای اصلی آموزشی کمک کند.




مدلهای زبان بزرگ (LLM) به ورودیها پاسخهای سریعی تولید میکنند. در حالی که این فرآیند برای ارائه پاسخهای صحیح به سوالات ساده مناسب است، ممکن است هنگامی که کاربر پرسشهای پیچیدهای مطرح میکند به همان اندازه کارساز نباشد. پاسخ به سوالات پیچیده — که قابلیت ضروری برای بارهای کاری هوش مصنوعی عاملانه است — نیازمند آن است که مدل زبان بزرگ پیش از ارائه پاسخ، درباره سوال استدلال کند.

این شبیه به شیوه تفکر اکثر انسانهاست — زمانی که از آنها خواسته شود دو به علاوه دو را جمع کنند، پاسخ فوری ارائه میدهند بدون اینکه نیاز به توضیح اصول اولیه جمع یا اعداد صحیح داشته باشند. اما اگر به صورت فوری از یک فرد خواسته شود که برنامه کسب و کاری تدوین کند که سود یک شرکت را 10٪ افزایش دهد، او احتمالاً گزینههای مختلف را مورد استدلال قرار داده و پاسخ چند مرحلهای ارائه میدهد.
مقیاسبندی زمان آزمایش، که به آن تفکر بلندمدت نیز گفته میشود، در هنگام استنتاج رخ میدهد. به جای مدلهای هوش مصنوعی سنتی که پاسخ یکباره و سریعی به ورودی کاربر تولید میکنند، مدلهایی که از این تکنیک استفاده میکنند، تلاش محاسباتی اضافی را در هنگام استنتاج اختصاص میدهند تا بتوانند قبل از رسیدن به بهترین پاسخ، از میان پاسخهای احتمالی متعدد استدلال کنند.
در وظایفی مانند تولید کد پیچیده و سفارشی برای توسعهدهندگان، این فرآیند استدلال هوش مصنوعی ممکن است چندین دقیقه یا حتی ساعت طول بکشد — و به راحتی میتواند بیش از 100 برابر محاسبات نسبت به یک گذر استنتاجی یکباره در یک مدل زبان بزرگ سنتی نیاز داشته باشد، که احتمالاً در اولین تلاش برای پاسخ به یک مشکل پیچیده پاسخ صحیحی تولید نمیکند.
این قابلیت محاسبات زمان آزمایش به مدلهای هوش مصنوعی امکان میدهد تا راهحلهای مختلفی برای یک مشکل بررسی کنند و درخواستهای پیچیده را به چندین مرحله تجزیه کنند — در بسیاری از موارد، در حین استدلال کار خود را به کاربر نشان میدهند. مطالعات نشان دادهاند که مقیاسبندی زمان آزمایش منجر به پاسخهای با کیفیت بالاتری میشود زمانی که مدلهای هوش مصنوعی ورودیهای باز و انتهایی دریافت میکنند که نیازمند چندین مرحله استدلال و برنامهریزی هستند.
روششناسی محاسبات زمان آزمایش دارای رویکردهای متعددی است، از جمله:
• اقدام به زنجیره تفکر (Chain-of-thought prompting): شکستن مسائل پیچیده به یک سری مراحل سادهتر.
• نمونهگیری با رأیگیری اکثریت: تولید پاسخهای متعدد برای همان ورودی، سپس انتخاب پاسخی که به طور مکرر تکرار شده به عنوان خروجی نهایی.
• جستجو: کاوش و ارزیابی مسیرهای متعدد موجود در ساختاری شبیه به درخت از پاسخها.
• روشهای پسآموزشی مانند نمونهگیری بهترین از میان n نیز میتوانند برای تفکر بلندمدت در هنگام استنتاج به منظور بهینهسازی پاسخها مطابق با ترجیحات انسانی یا اهداف دیگر استفاده شوند.
افزایش محاسبات زمان آزمایش این امکان را فراهم میکند که هوش مصنوعی پاسخهای بهخوبی استدلال شده، مفید و دقیقتری به پرسشهای پیچیده و باز کاربران ارائه دهد. این قابلیتها برای وظایف استدلال دقیق و چند مرحلهای که از هوش مصنوعی عاملانه و فیزیکی مستقل انتظار میرود، حیاتی خواهند بود. در صنایع مختلف، آنها میتوانند با ارائه دستیارانی بسیار توانمند برای تسریع کار، بهرهوری و کارایی را افزایش دهند.

در حوزه بهداشت و درمان، مدلها میتوانند از مقیاسبندی زمان آزمایش برای تحلیل حجم عظیمی از دادهها و استنباط نحوه پیشرفت یک بیماری استفاده کنند، و همچنین عوارض احتمالی ناشی از درمانهای جدید بر اساس ساختار شیمیایی یک مولکول دارویی را پیشبینی کنند. یا میتوانند یک پایگاه داده از آزمایشات بالینی را بررسی کنند تا گزینههایی متناسب با پروفایل بیماری فرد پیشنهاد دهند، در حالی که فرآیند استدلال خود را در مورد مزایا و معایب مطالعات مختلف به اشتراک میگذارند.
در خردهفروشی و لجستیک زنجیره تأمین، تفکر بلندمدت میتواند به تصمیمگیریهای پیچیده مورد نیاز برای مقابله با چالشهای عملیاتی کوتاهمدت و اهداف راهبردی بلندمدت کمک کند. تکنیکهای استدلال میتوانند به کسب و کارها در کاهش ریسک و مقابله با چالشهای مقیاسپذیری از طریق پیشبینی و ارزیابی همزمان چندین سناریو کمک کنند — که میتواند به پیشبینی دقیقتر تقاضا، مسیرهای بهینهتر در زنجیره تأمین و تصمیمات منبعیابی متناسب با ابتکارات پایداری یک سازمان منجر شود.
و برای شرکتهای جهانی، این تکنیک میتواند در تدوین برنامههای کسب و کار دقیق، تولید کدهای پیچیده برای اشکالزدایی نرمافزار یا بهینهسازی مسیرهای حرکت کامیونهای تحویل، رباتهای انباری و رباتتاکسیها به کار رود.
مدلهای استدلال هوش مصنوعی به سرعت در حال تحول هستند. OpenAI o1-mini و o3-mini، DeepSeek R1 و Gemini 2.0 Flash Thinking از DeepMind گوگل در چند هفته گذشته معرفی شدند و انتظار میرود مدلهای جدید دیگری نیز به زودی عرضه شوند. مدلهایی از این دست به طور قابل توجهی نیاز به محاسبات بیشتری در هنگام استنتاج برای استدلال و تولید پاسخهای صحیح به پرسشهای پیچیده دارند — که به این معناست که شرکتها باید منابع محاسباتی شتابدار خود را افزایش دهند تا نسل بعدی ابزارهای استدلال هوش مصنوعی که قادر به پشتیبانی از حل مسائل پیچیده، کدنویسی و برنامهریزی چند مرحلهای هستند، ارائه دهند.
